Natuurlijke Taalverwerking (NLP) in Python met NLTK: Een Inleiding
Inleiding
Deze handleiding gaat over natuurlijke taalverwerking (NLP) in Python met het uitstekende NLTK-pakket. Natuurlijke taalverwerking is een onderdeel van kunstmatige intelligentie dat zich bezighoudt met het ontwikkelen van toepassingen en diensten die de mogelijkheid hebben om natuurlijke (of menselijke) talen te begrijpen, bijvoorbeeld spraakherkenning in apparaten zoals Alexa en Google Home, en sentimentanalyse van tweets op Twitter om de stemming van investeerders te peilen. De uitdaging bij het begrijpen van natuurlijke talen is dat de gegevens ongestructureerd zijn. Ze komen niet in een formaat dat gemakkelijk te analyseren en interpreteren is. Natuurlijke taalverwerking is het proces waarbij een stuk tekst wordt omgezet in een gestructureerd formaat dat een computer kan verwerken en begrijpen. Het is een zeer spannend gebied binnen machinaal leren.
Voordelen van NLP
Elke dag worden er miljoenen nieuwe woorden geschreven op blogs, sociale netwerksites en webpagina's. Bedrijven gebruiken deze data om te begrijpen wat hun gebruikers leuk vinden en passen hun strategieën in real-time aan.
Stel dat iemand van reizen houdt en regelmatig op sociale media over zijn reisplannen post. Deze gebruikersinteracties worden gebruikt om hem relevante advertenties te tonen van online hotel- en vluchtboekingsapps.
Er zijn veel meer manieren waarop NLP kan worden gebruikt. Online winkeliers zoals Amazon kunnen bijvoorbeeld productreviews analyseren om hun sorteeralgoritmen te verbeteren. Overheden kunnen actieplannen maken op basis van grootschalige enquêtes. Journalisten zijn wellicht geïnteresseerd in de sentimenten van kiezers over bepaalde onderwerpen of kandidaten tijdens de verkiezingstijd.
NLP-implementaties
Enkele van de meest voorkomende toepassingen van NLP zijn:
Zoekmachines zoals Google en Yahoo.
Zoekmachines begrijpen uit je geschiedenis dat je geïnteresseerd bent in technologie en passen hun zoekresultaten daarop aan.Sociale media feeds zoals die van Facebook en Twitter. Het algoritme dat je feed genereert, begrijpt je interesses met behulp van natuurlijke taalverwerking en toont je relevante advertenties en berichten.
Spraakassistenten zoals Apple Siri en Alexa.
Spamfilters in je e-mailinbox. In plaats van alleen naar bepaalde trefwoorden te zoeken, verwerken moderne spamfilters de inhoud van de e-mail en bepalen vervolgens of het spam is.
Zoals je ziet, zijn er veel gebieden waar natuurlijke taalverwerking nuttig is. In deze handleiding zullen we enkele van de belangrijkste elementen bespreken.
Installatie van het NLTK-pakket in Python
In deze handleiding gebruiken we Python 3. Eerst controleren we of de juiste compilers geïnstalleerd zijn door een terminalvenster te openen en het volgende commando uit te voeren:
python -v
We maken een nieuwe map aan voor ons project en navigeren ernaartoe:
mkdir nlp-tutorial
cd nlp-tutorial
Nu kunnen we de Python-bibliotheek installeren die we gaan gebruiken, namelijk de Natural Language Toolkit (NLTK). Deze NLTK-pakket wordt ondersteund door een actieve open-source community en bevat veel hulpprogramma's voor taalverwerking. We kunnen het installeren met behulp van het pip-commando:
pip install nltk
Vervolgens moeten we de benodigde data binnen NLTK downloaden. Dit doen we door de volgende code in een nieuw Python-bestand op te nemen:
import nltk
nltk.download()
Er zou een venster moeten openen dat er ongeveer zo uitziet. Omdat het een grote bibliotheek is, kunnen we ervoor kiezen om alleen de delen te downloaden die we nodig hebben. Hier selecteren we de boekencollectie en klikken op downloaden.
Dit voltooit onze eerste setup en we kunnen aan de slag met NLTK in Python.
Gegevensset
Om te beginnen met onze introductie tot natuurlijke taalverwerking, hebben we eerst wat data nodig om mee te werken. In de praktijk kunnen we onze eigen datasets maken door het web te scrapen of bestaande bestanden te downloaden. Maar voor nu zullen we een van de grote datasets gebruiken die in de NLTK-bibliotheek zitten. Deze bevatten klassieke romans, filmscripts, encyclopedieën, en zelfs gesprekken die in Londen zijn opgevangen. We gebruiken een set met filmrecensies voor onze analyse.
We beginnen met het importeren van de dataset en roepen een ‘readme’ functie aan om het onderliggende structuur van de data te begrijpen.
from nltk.corpus import movie_reviews
movie_reviews.readme()
We proberen de data te begrijpen door simpelweg woorden en hun frequenties te printen. We gebruiken de raw functie om de hele verzameling recensies als één grote brok data te krijgen:
raw = movie_reviews.raw()
print(raw)
plot : twee tienerstellen gaan naar een kerkfeest, drinken en rijden vervolgens. ze krijgen een ongeluk. een van de jongens sterft, maar zijn vriendin blijft hem zien in haar leven en krijgt nachtmerries. wat is de deal? kijk de film en "een soort van" kom erachter... kritiek: een mind-fuck film voor de tienergeneratie die een heel cool idee aanstipt, maar het in een heel slechte verpakking presenteert.
Zoals je kunt zien, levert dit de data zonder enige opmaak. We kunnen ook kiezen om alleen het eerste element te printen. De uitvoer is dan een enkel karakter.
print(raw[0])
p
Duidelijk is dat een enkele brok niet het formaat is waarin we de data willen hebben. We gebruiken de ‘words’ functie om de data op te splitsen in afzonderlijke woorden en slaan ze allemaal op in één 'woordenboek'.
dictionary = movie_reviews.words()
print(dictionary)
['plot', ':', 'twee', 'tiener', 'stellen', 'gaan', 'naar', ...]
Nu kunnen we statistieken zoals afzonderlijke woorden en hun frequentie in het woordenboek analyseren. We berekenen de frequentieverdeling (het aantal keren dat elk woord in het woordenboek voorkomt) en printen of plotten de top 50 woorden. Dit laat zien welke woorden het meest voorkomen.
from nltk import FreqDist
freq_dist = FreqDist(corpus)
print(freq_dist)
FreqDist met 39768 voorbeelden en 1583820 uitkomsten
print(freq_dist.most_common(50))
77717), ('de', 76529), ('.', 65876), ('een', 38106), ('en', 35576), ('van', 34123), ('naar', 31937), ("'", 30585), ('is', 25195), ('in', 21822), ('s', 18513), ('"', 17612), ('het', 16107), ('dat', 15924), ('-', 15595), (')', 11781), ('(', 11664), ('als', 11378), ('met', 10792), ('voor', 9961), ('zijn', 9587), ('deze', 9578), ('film', 9517), ('ik', 8889), ('hij', 8864), ('maar', 8634), ('op', 7385), ('zijn', 6949), ('t', 6410), ('door', 6261), ('be', 6174), ('een', 5852), ('film', 5771), ('een', 5744), ('die', 5692), ('niet', 5577), ('je', 5316), ('uit', 4999), ('bij', 4986), ('was', 4940), ('hebben', 4901), ('zij', 4825), ('heeft', 4719), ('haar', 4522), ('alle', 4373), ('?', 3771), ('daar', 3770), ('zoals', 3690), ('dus', 3683), ('uit', 3637)]
freq_dist.plot(50)
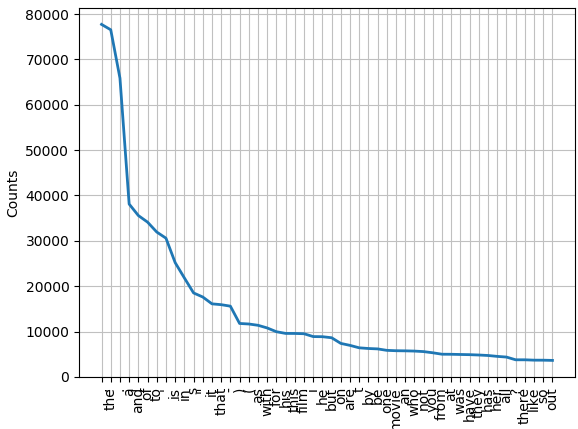
Dit vertelt ons hoeveel totale woorden er in ons woordenboek staan (1.583.820 uitkomsten) en hoeveel unieke woorden het bevat (39.768 voorbeelden). We krijgen ook een blik op de top 50 meest voorkomende woorden en hun frequentie-grafiek.
Echter, realiseren we ons dat eenvoudige analyse van de tekst in zijn natuurlijke formaat niet veel bruikbare resultaten oplevert – het vaak voorkomen van interpunctie en veelvoorkomende woorden als ‘de’ en 'van' helpen ons niet om de context of betekenis van de tekst te begrijpen. In de volgende secties zullen we enkele veelgebruikte en nuttige stappen in NLP uitleggen, die ons toestaan de tekst om te zetten in een formaat dat effectiever geanalyseerd kan worden.
Tokenisatie
Eerder, toen we de ruwe tekst in afzonderlijke woorden splitsten, maakten we gebruik van het concept van tokenisatie. Het idee van tokenisatie is om een tekstdocument te nemen en het op te splitsen in afzonderlijke 'tokens' (vaak woorden of groepen woorden) en deze apart op te slaan. Voordat we deze tokens opslaan, kunnen we ook wat kleine opmaakmethoden toepassen. Bijvoorbeeld, interpunctie kan verwijderd worden.
Laten we dit testen op een individuele recensie. Eerst splitsen we onze ruwe tekst niet per woord, maar per recensie.
reviews = []
for i in range (0,len(movie_reviews.fileids())):
reviews.append(movie_reviews.raw(movie_reviews.fileids()[i]))
In ons ruwe document krijgt elke filmrecensie een unieke bestands-ID. Deze 'for'-loop gaat door elke bestands-ID en voegt de ruwe tekst die aan die ID is verbonden toe aan een 'reviews'-lijst. We kunnen nu afzonderlijke recensies bekijken, bijvoorbeeld, om de eerste recensie alleen te zien:
print(reviews[0])
plot : twee tienerstelletjes gaan naar een kerkfeest, drinken en gaan dan rijden.
ze krijgen een ongeluk.
een van de jongens sterft, maar zijn vriendin blijft hem zien in haar leven en heeft nachtmerries.
wat is er aan de hand?
kijk de film en 'soort van' kom erachter...
kritiek: een mind-fuck film voor de tienergeneratie die een heel gaaf idee aanraakt, maar het presenteert in een heel slecht pakket.
wat deze recensie nog moeilijker maakt om te schrijven, omdat ik films die proberen het mold te doorbreken, je hoofd in de war te brengen, en dergelijke (lost highway & memento) over het algemeen toejuich, maar er zijn goede en slechte manieren om alle soorten films te maken, en deze mensen hebben deze gewoon verkeerd aangegrepen.
ze lijken dit best coole concept te hebben genomen, maar hebben het verschrikkelijk uitgevoerd.
Nu we de afzonderlijke recensies in hun natuurlijke vorm hebben, kunnen we het nog verder opsplitsen met tokenizer-methoden in de NLTK-bibliotheek. De 'sent_tokenize'-functie splitst de recensie in zinsdelen, en 'word_tokenize' splitst de recensie in woorden.
from nltk.tokenize import word_tokenize, sent_tokenize
sentences = nltk.sent_tokenize(reviews[0])
words = nltk.word_tokenize(reviews[0])
print(sentences[0])
plot : twee tienerstelletjes gaan naar een kerkfeest, drinken en gaan dan rijden.
Er zijn veel opties om te tokenizen met NLTK waar je over kunt lezen in de API-documentatie hier. Voor onze doeleinden verwijderen we interpunctie met een reguliere-expressie-tokenizer en gebruiken we de Python-functie om strings om te zetten naar kleine letters om onze uiteindelijke tokenizer te maken.
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer(r'\w+')
tokens = tokenizer.tokenize(reviews[0].lower())
print(tokens)
['plot', 'twee', 'tiener', 'stelletjes', 'gaan', 'naar', 'een', 'kerk', 'feest', 'drinken', 'en', 'dan', 'rijden', 'ze', 'krijgen', 'een', 'ongeluk', 'een', 'van', 'de', 'jongens', 'sterft', 'maar', 'zijn', 'vriendin', 'blijft', 'hem', 'zien', 'in', 'haar', 'leven', 'en', 'heeft', 'nachtmerries', 'wat', 's', 'er', 'aan', 'de', 'hand', 'kijk', 'de', 'film', 'en', 'soort', 'van', 'kom', 'er', 'achter', 'kritiek', 'een', 'mind', 'fuck', 'film', 'voor', 'de', 'tiener', 'generatie', 'die', 'een', 'heel', 'gaaf', 'idee', 'aanraakt', 'maar', 'het', 'presenteert', 'in', 'een', 'heel', 'slecht', 'pakket', 'wat', 'is', 'wat', 'maakt', 'deze', 'recensie', '...']
Stopwoorden
We hebben nu een meer beknopte weergave van de reviews; een die alleen de nuttige delen van de ruwe tekst bevat. We hebben onze reviews succesvol opgedeeld in tokens - woorden en zinnen. Een belangrijke stap in NLP is het verwijderen van een categorie genaamd 'stopwoorden', zoals 'de', 'en', 'naar'. Deze woorden komen te vaak voor in allerlei teksten om enige significante waarde toe te voegen op het gebied van context of betekenis. Om dit te implementeren, kunnen we onze tekst vergelijken met een vooraf gedefinieerde lijst van stopwoorden en de overeenkomende woorden verwijderen. Voor een meer gedetailleerde handleiding over het verwerken van tekst in Python, kun je onze Sentiment analyse tutorial in Python: beoordelen van reviews over films en producten raadplegen.
from nltk.corpus import stopwords
tokens = [token for token in tokens if token not in stopwords.words('dutch')]
print(tokens)
['verhaal', 'twee', 'tiener', 'stellen', 'gaan', 'kerk', 'feest', 'drinken', 'rijden', 'ongeluk', 'een', 'jongens', 'overlijdt', 'vriendin', 'blijft', 'zien', 'leven', 'nachtmerries', 'omgaan', 'film', 'kijken', 'soort', 'kritiek', 'denken', 'verwarde', 'film', 'tiener', 'generatie', 'aanspreken', 'coole', 'idee', 'slecht', 'pakket', 'maakt', 'recensie', 'moeilijker', 'een', 'schrijven', 'aangezien', 'applaus', 'films', 'poging' ...]
Als we ons richten op de eerste review, zien we dat het aantal tokens daalt van 726 naar 343 - dus bijna de helft van de woorden in deze review waren eigenlijk overbodig.
Lemmatizatie en Stemming
Engels is een grappige taal. Vaak hebben verschillende variaties van een woord dezelfde algemene betekenis (tenminste voor onze analyse), en daarom kan het handig zijn om ze samen te groeperen als één. In plaats van de woorden 'praat', 'praat', 'gepraat', 'pratend' apart te behandelen, kunnen we ervoor kiezen om ze allemaal als hetzelfde woord te behandelen. Er zijn twee veelgebruikte methoden om dit te doen – lemmatisering en stemming.
Lemmatisering lijkt op wat een mens zou doen. Het neemt een verbogen vorm van een woord en geeft de basisvorm terug – de lemma. Om dit te bereiken, hebben we enige context nodig over hoe het woord wordt gebruikt, zoals of het een zelfstandig naamwoord, bijvoeglijk naamwoord, werkwoord of bijwoord is. Stemming daarentegen is een veel ruwer proces en geeft vaak een woord terug dat gewoon de eerste paar letters bevat die door iedere vorm van het woord gedeeld worden (maar niet altijd een echt woord is). Laten we een voorbeeld bekijken.
Eerst importeren en definiëren we een stemmer en een lemmatizer uit de NLTK-bibliotheek. Vervolgens printen we het basiswoord dat door elk benadering wordt gegenereerd.
from nltk.stem import PorterStemmer, WordNetLemmatizer
stemmer = PorterStemmer()
lemmatizer = WordNetLemmatizer()
test_word = "worrying"
word_stem = stemmer.stem(test_word)
word_lemmatise = lemmatizer.lemmatize(test_word)
word_lemmatise_verb = lemmatizer.lemmatize(test_word, pos="v")
word_lemmatise_adj = lemmatizer.lemmatize(test_word, pos="a")
print("Stem:",word_stem,"\nLemma:", word_lemmatise, word_lemmatise_verb, word_lemmatise_adj)
Stem: worri
Lemma: worrying worry worrying
Zoals we al dachten, heeft de stemmer gekozen voor het woord 'worri', wat geen woord is dat door het woordenboek wordt erkend, maar een gestemde versie van de verschillende vormen van het woord 'worry'. Aan de andere kant moet onze lemmatizer weten of het woord als bijvoeglijk naamwoord of werkwoord is gebruikt om het correct te lemmatiseren. Maar zodra het deze informatie krijgt, werkt het zoals verwacht. Het proces van het toevoegen van deze extra informatie in de vorm van contextuele labels wordt deel-van-spraak tagging genoemd en wordt in de volgende sectie uitgelegd. Hoewel deze kleine oefening misschien heeft laten zien dat stemming een minder ideale benadering is, blijkt dat het in de praktijk gelijksoortig of nauwelijks slechter presteert. Je kunt dit zelf testen met andere woorden, zoals 'walking', en merken dat de stemmer en de lemmatizer dezelfde resultaten zullen geven.
Woordsoortentagging
Zoals hierboven vermeld, is het taggen van woorden met een grammaticale categorie het doel van part-of-speech tagging. Om dit te doen hebben we context nodig in de zin waarin het woord verschijnt – bijvoorbeeld, welke woorden ernaast staan en hoe de betekenis hier van afhangt. Gelukkig heeft de NLTK-bibliotheek een functie waarmee we alle mogelijke part-of-speech tags kunnen bekijken.
nltk.help.upenn_tagset()
De volledige lijst bevat PoS-tags zoals VB (werkwoord in de basisvorm), VBG (werkwoord als tegenwoordig deelwoord), enzovoort.
We gebruiken simpelweg de 'pos-tag' functie om deze tags voor onze tokens te genereren:
De volledige lijst bevat PoS-tags zoals VB (werkwoord in de basisvorm), VBG (werkwoord als tegenwoordig deelwoord), enzovoort.
from nltk import pos_tag
pos_tokens = nltk.pos_tag(tokens)
print(pos_tokens)
[('plot', 'NN'), ('two', 'CD'), ('teen', 'NN'), ('couples', 'NNS'), ('go', 'VBP'), ('church', 'NN'), ('party', 'NN'), ('drink', 'VBP'), ('drive', 'JJ'), ('get', 'NN'), ('accident', 'JJ'), ('one', 'CD'), ('guys', 'NN'), ('dies', 'VBZ'), ('girlfriend', 'VBP'), ('continues', 'VBZ'), ('see', 'VBP'), ('life', 'NN'), ('nightmares', 'NNS'), ('deal', 'VBP'), ('watch', 'JJ'), ('movie', 'NN'), ('sorta', 'NN'), ('find', 'VBP'), ('critique', 'JJ'), ('mind', 'NN'), ('fuck', 'JJ'), ('movie', 'NN'), ('teen', 'JJ'), ('generation', 'NN'), ('touches', 'NNS'), ('cool', 'VBP'), ('idea', 'NN'), ('presents', 'NNS'), ('bad', 'JJ'), ('package', 'NN'), ('makes', 'VBZ'), ('review', 'VB'), ('even', 'RB'), ('harder', 'RBR'), ('one', 'CD'), ('write', 'NN'), ('since', 'IN'), ('generally', 'RB'), ('applaud', 'VBN'), ('films', 'NNS'), ('attempt', 'VB'), ('break', 'JJ'), ('mold', 'NN'), ('mess', 'NN'), ('head', 'NN'), ('lost', 'VBD'), ('highway', 'RB'), ('memento', 'JJ'), ('good', 'JJ'), ('bad', 'JJ'), ('ways', 'NNS'), ('making', 'VBG'), ('types', 'NNS'), ('films', 'NNS'), ('folks', 'NNS'), ('snag', 'VBP'), ('one', 'CD'), ('correctly', 'RB'), ('seem', 'VBP'), ('taken', 'VBN'), ('pretty', 'RB'), ('neat', 'JJ'), ('concept', 'NN'), ('executed', 'VBD'), ('terribly', 'RB'), ('problems', 'NNS'), ('movie', 'NN'), ('well', 'RB'), ('main', 'JJ'), ('problem', 'NN'), ('simply', 'RB'), ('jumbled', 'VBD'), ('starts', 'NNS'), ('normal', 'JJ'), ('downshifts', 'NNS'), ('fantasy', 'JJ'), ('world', 'NN'), ('audience', 'NN'), ('member', 'NN'), ('idea', 'NN'), ('going', 'VBG'), ('dreams', 'JJ'), ('characters', 'NNS'), ('coming', 'VBG'), ('back', 'RB'), ('dead', 'JJ'), ('others', 'NNS'), ('look', 'VBP'), ('like', 'IN'), ('dead', 'JJ'), ('strange', 'JJ') ...]
Woordenschat
Tot nu toe hebben we onze NLP-tools getest op individuele recensies, maar de echte test zou zijn om alle recensies samen te gebruiken. Als we dit zouden doen, zou ons woordenboek in totaal 1.336.782 woordtokens bevatten. Maar deze lijst kan meerdere keren hetzelfde woord bevatten. Bijvoorbeeld de zin “They talked and talked” genereert de tokens [‘They’, ‘talked’, ‘and’, ‘talked’]. Dit was erg handig bij het tellen van frequenties, maar het kan nuttiger zijn om een verzameling van alle unieke woorden in het woordenboek te hebben, bijvoorbeeld [‘They’, ‘talked’, ‘and’]. Hiervoor kunnen we een ingebouwde Python-functie genaamd ‘set’ gebruiken.
dictionary_tokens = tokenizer.tokenize(raw.lower())
vocab = sorted(set(dictionary_tokens))
Met behulp van deze functie kunnen we de algemene woordenschat (de unieke woorden) in een tekst bekijken. Dit kan helpen om de grootte van de woordenschat van verschillende teksten te vergelijken, of om te kijken welk percentage van de woordenschat over een bepaald onderwerp gaat. Bijvoorbeeld, terwijl het totale aantal woorden in het woordenboek van recensies 1.336.782 is (na tokenisatie), is de grootte van de woordenschat 39.696. Deze kleinere verzameling woorden kan in bepaalde situaties een betere representatie van de ruwe tekst zijn.
print("Tokens:", len(dictionary_tokens))
Tokens: 1336782
print("Vocabulary:", len(vocab))
Vocabulary: 39696
Conclusie
In deze tutorial hebben we een dataset van filmrecensies omgevormd van rauwe tekst naar een gestructureerd formaat dat een computer kan begrijpen en analyseren. Deze gestructureerde vorm is ideaal voor data-analyse of als input voor machine learning-algoritmes die zich richten op besproken onderwerpen, de stemming van de recensieschrijver analyseren, of verborgen betekenissen ontdekken. Hier gaan we dieper op in in de volgende natural language processing tutorial over sentimentanalyse.
Als je niet verder gaat met bovenstaande tutorial, ga dan gerust verder en gebruik de besproken NLP-concepten om zelf met tekstdata aan de slag te gaan! De filmrecensiesdataset die we gebruikten, is al gelabeld als positieve en negatieve recensies. Een interessant project zou zijn om de tools van deze tutorial te gebruiken om een machine learning-classifier te bouwen die het label kan voorspellen van een nieuwe filmrecensie, bijvoorbeeld van IMDb.
Delen