Optische tekenherkenning (OCR) met Python en Tesseract 4: Een introductie
Inleiding
Deze handleiding is een introductie tot optische tekenherkenning (OCR) met Python en Tesseract 4. Tesseract is een uitstekend programma dat al tientallen jaren in ontwikkeling is, en het begon in de jaren '70 bij IBM, en meer recentelijk bij Google. Ten tijde van het schrijven (november 2018) was er een nieuwe versie van Tesseract uitgebracht - Tesseract 4 - die gebruik maakt van modellen die zijn getraind met deep learning om tekst te herkennen. Deze versie kan niet alleen met grote nauwkeurigheid gescande tekst herkennen, maar ook handgeschreven tekst, en presteert veel beter dan Tesseract 3. OCR is vooral nuttig voor gescande afbeeldingen die tekst bevatten. Historische documenten, bijvoorbeeld, zijn vaak beschikbaar in gescande vorm, maar zijn nog niet gedigitaliseerd. Je wilt misschien ook zelf documenten scannen en de inhoud eruit halen voor analyse.
Tesseract installeren
Installatie op Unix-systemen
Het installeren van Tesseract op Unix-systemen is redelijk eenvoudig, want je kunt kant-en-klare bestanden downloaden. Op Mac OS X kun je het installeren met:
brew install tesseract --HEAD
De parameter --HEAD zorgt ervoor dat je de nieuwste versie van Tesseract 4 krijgt, die deze maand niet meer in beta is.
En op Ubuntu kan het worden geïnstalleerd als volgt:
sudo apt install tesseract-ocr
sudo apt install libtesseract-dev
Werk je op een andere Linux-distributie, raadpleeg dan de installatiehandleiding hier:
https://github.com/tesseract-ocr/tesseract/wiki.
Installatie op Windows
Op Windows moet je een installatieprocedure doorlopen.
Als je een andere taal dan Engels wilt gebruiken, kun je extra schrift- en taalgegevens downloaden tijdens het gebruik van de installer. Standaard wordt Tesseract niet aan de PATH-variabele toegevoegd, wat betekent dat je naar de installatiemap van Tesseract moet gaan om daaruit te werken. Je kunt het bestand tesseract.exe ook toevoegen aan de PATH-omgeving, zodat het overal in Windows te gebruiken is.
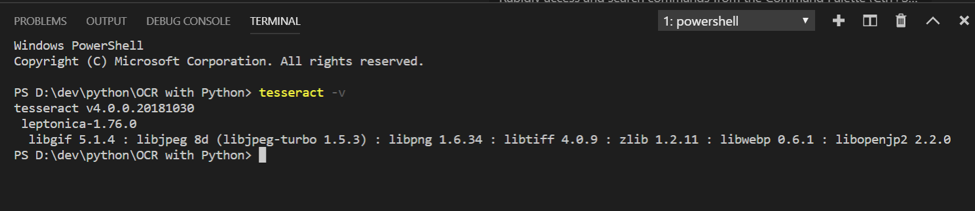
Installatie verifiëren
Om te controleren of je Tesseract correct hebt geïnstalleerd, voer het volgende commando uit in de terminal. Het zou de Tesseract-versie en de lijst van compatibele bibliotheken moeten tonen.
Het gebruik van de Tesseract standalone binary
Tesseract is een op zichzelf staand programma, dat geen Python-omgeving nodig heeft. Er zijn echter wel wrappers beschikbaar voor Tesseract in Python, waar we later op terugkomen. Eerst gaan we het gebruik van de Tesseract-tool laten zien door het een afbeelding te geven met duidelijke tekst.
Een dergelijke afbeelding moet bij voorkeur een hoge resolutie of DPI hebben. Hieronder is er een afbeelding waar de achtergrond duidelijk gescheiden is van de tekst, wat het een relatief gemakkelijke afbeelding maakt voor een optical character recognition (OCR) taak.
img src="/images/ocr-tesseract-sample-text.png" alt="Voorbeeld Afbeelding">
Sla de afbeelding op door met de rechtermuisknop te klikken en 'Afbeelding opslaan als' te kiezen. Voer dan het volgende commando in je terminal of PowerShell in Windows in (voeg 'stdout' zonder haakjes toe aan het eind van de regel als je in Windows werkt):
tesseract pad naar de
Je zou een resultaat moeten zien dat lijkt op de afbeelding hieronder. Tesseract heeft de tekst "Dit is een voorbeeldtekst voor Tesseract om te herkennen" met 100% nauwkeurigheid uit de afbeelding gehaald.
img src="/images/tesseract-output-sample-text.png" alt="Voorbeeld Output">
Als er ruis in een afbeelding zit, zoals een wazige achtergrond, werkt Tesseract over het algemeen nog steeds goed, maar het kan moeite hebben met bepaalde karakters. Het kan zijn dat sommige letters niet worden herkend of dat vlekken als letters worden geclassificeerd. Het is dan nodig om de ruis te verwijderen voor de OCR, door technieken toe te passen vanuit feature extraction of machine learning algoritmen om de ruis van de tekst te scheiden, wat je kunt doen met wat Python-code.
Hiervoor draai je Tesseract niet als zelfstandig programma vanuit de shell, maar moet Tesseract geïntegreerd worden in een groter codeframewerk, wat we in de volgende sectie zullen bekijken door gebruik te maken van Tesseract wrappers in Python. Daarmee kun je ook apps schrijven die Tesseract en OCR gebruiken, zoals mobiele scanner apps.
Tesseract gebruiken in Python
Installeren van Pytesseract
Pytesseract is een geweldige tool om Tesseract te gebruiken. Een alternatief is TesserOCR, maar die werkt alleen met Tesseract 3 en is nog niet bijgewerkt voor Tesseract 4. We gebruiken pip om Pytesseract te installeren. Het is handig om een virtuele omgeving te gebruiken zodat je verschillende projecten gescheiden kunt houden, maar het is niet per se noodzakelijk. Voer de volgende opdrachten in je command prompt uit:
pip install virtualenv
virtualenv env
Je kunt elke naam gebruiken in plaats van “env”. Vervolgens activeer je de virtuele omgeving in de shell (maar dit kun je ook overslaan):
source activate env/activate/bin
Als de omgeving geactiveerd is, zou je terminal moeten beginnen met (env), bijvoorbeeld:
- (env) D:\dev\
We gaan ook pillow installeren, een image processing bibliotheek in Python, samen met pytesseract:
pip install pillow
pip install pytesseract
Gebruik
Maak een Python-bestand, bijvoorbeeld 'ocr.py', of een nieuwe Jupyter notebook met de volgende code:
import os
from PIL import Image
import pytesseract
import argparse
import cv2
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True, help="pad naar de afbeelding die verwerkt wordt door OCR / tesseract")
ap.add_argument("-p", "--preprocess", type=str, default="thresh", help="voorbewerkingsmethode die toegepast wordt op de afbeelding")
args = vars(ap.parse_args())
De eerste 5 regels importeren de benodigde bibliotheken. Om een afbeelding te laden en te verwerken met Python en PyTesseract, hebben we de Image klasse van de PIL bibliotheek nodig. De rest van de regels worden gebruikt om de argumenten te verwerken die we vanaf de command line meegeven bij het uitvoeren van het Python-bestand. De argumenten zijn:
- image: Het systeem pad naar de afbeelding die verwerkt wordt door OCR / tesseract
- preprocess: De voorbewerkingsmethode die wordt toegepast op de afbeelding, ofwel "thresh" of "blur". Meer methoden zijn beschikbaar, maar deze twee worden het vaakst gebruikt en zijn voldoende voor deze handleiding.
Nu laden we de afbeelding in het geheugen van de Python kernel. Omdat we geen kleuren nodig hebben voor OCR, transformeren we deze naar grijstinten. We gebruiken het OpenCV pakket hiervoor. Daarna slaan we de nieuw verwerkte afbeelding op.
# De afbeelding wordt in het geheugen geladen
image = cv2.imread(args["image"])
# Converteren naar grijstinten
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Voorbereiden van de afbeelding
if args["preprocess"] == "thresh": gray = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
# Vervagen van de afbeelding om ruis te verwijderen
elif args["preprocess"] == "blur": gray = cv2.medianBlur(gray, 3)
# Schrijf de nieuwe grijstinten afbeelding naar schijf
filename = "{}.png".format(os.getpid())
cv2.imwrite(filename, gray)
Het doel van de thresh methode hierboven is om de tekst op de voorgrond te onderscheiden van de achtergrond. De methode blur helpt ook om ruis te verminderen. Vervolgens laden we de afbeelding opnieuw en voeren deze door Tesseract met behulp van de pytesseract wrapper:
# Laad de afbeelding als een PIL/Pillow afbeelding, voer OCR uit
text = pytesseract.image_to_string(Image.open(filename))
print(text)
# Toon de output afbeelding
cv2.imshow("Image", image)
cv2.imshow("Output", gray)
cv2.waitKey(0)
De 'pytesseract.image_to_string' haalt de tekststring uit de grijstinten afbeelding en slaat deze op in de 'text' variabele. Je kunt daarna de tekst verder verwerken, bijvoorbeeld door een spellingscontrole uit te voeren om letters die verkeerd geïdentificeerd zijn door Tesseract te corrigeren. Dit is de basisopzet van een Python-bestand dat Tesseract incorporeert om een afbeelding te laden, ruis te verwijderen en OCR toe te passen.
We zullen nu deze stappen en enkele verdere ruisverwijderingstechnieken toepassen om tekst te extraheren uit een afbeelding met zowel een rommelige als wazige achtergrond en wazige tekst.
OCR met wazige en onscherpe afbeeldingen
We gaan proberen OCR toe te passen op de afbeelding hieronder.

In deze afbeelding is er geen schoon, helder witte achtergrond. In plaats daarvan overlapt de achtergrond een beetje met de tekst. Het menselijk oog kan de tekst nog goed identificeren, dus Tesseract zou dat, dankzij de training met deep learning, ook moeten kunnen.
Klik met de rechtermuisknop op de afbeelding, kies 'Afbeelding opslaan als' en sla het op in een map met de bestandsnaam 'ocr-noise-text-1.png'.
Nu voeren we het uit via de Tesseract binary zonder enige voorbewerking, gebruikmakend van de eerdere code om Tesseract in de shell uit te voeren:
tesseract ocr-noise-text-1.png
Zoals je kan zien aan de rommelige output, kan Tesseract de tekst niet nauwkeurig extraheren.
We gaan nu de afbeelding voorbewerken om de tekst zoveel mogelijk te laten uitkomen ten opzichte van de achtergrond. Dit doen we met een combinatie van thresholding en morfologische aanpassingen. We gebruiken hiervoor opnieuw OpenCV.
Zoals eerder wordt de afbeelding eerst omgezet naar grijstinten. Vervolgens wordt er een Gaussian Blur toegepast om ruis verder weg te nemen. De andere handelingen hebben betrekking op de tekst zelf, zoals thresholden en dilateren om de tekst van de achtergrond te scheiden. De laatste stap keert de kleuren om, zodat de tekst zwart is en op een witte achtergrond wordt weergegeven. Zie voor een uitstekende oplossing op StackOverflow hier.
import cv2
image = cv2.imread('./ocr-noise-text-1.png', 0)
imgBlur = cv2.GaussianBlur(image, (9, 9), 0)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))
imgTH = cv2.morphologyEx(imgBlur, cv2.MORPH_TOPHAT, kernel)
imgBin = cv2.threshold(imgTH, 0, 250, cv2.THRESH_OTSU)
imgdil = cv2.dilate(imgBin, kernel)
imgBin_Inv = cv2.threshold(imgdil, 0, 250, cv2.THRESH_BINARY_INV)
cv2.imwrite('./ocr-noise-text-2.png', imgBin_Inv)
cv2.waitKey(0)
De nieuwe, ruis-gecorrigeerde afbeelding zonder de wazige achtergrond wordt opgeslagen als 'ocr-noise-text-2.png'. Het ziet er dan als volgt uit:

Nu voeren we deze afbeelding uit via pytesseract, met de volgende code, vergelijkbaar met de eerdere:
text = pytesseract.image_to_string(Image.open(‘./ocr-noise-text-2.png’))
print(text)
Zoals je aan de output kunt zien, haalt Tesseract nu correct de tekst uit de afbeelding, ook al is de tekst zelf nog wazig en zijn sommige pixels in de letters losgekoppeld. Dankzij het voorbewerken van de afbeelding presteert het voor-getrainde model van Tesseract, dat getraind is met miljoenen karakters, verrassend goed. Dus machine learning is heel nuttig voor OCR-doeleinden.
Conclusie
Deze tutorial is een eerste stap in optische tekenherkenning (OCR) in Python. We gebruiken het uitstekende Tesseract-pakket om tekst uit een gescande afbeelding te halen. Deze techniek is handig voor vele situaties. Denk bijvoorbeeld aan historische documenten die nog niet digitaal zijn vastgelegd of fout zijn gedigitaliseerd.
Er zijn alternatieven voor Tesseract zoals de Google Vision API of Abbyy, maar deze zijn niet gratis en open source. Je kunt vaak de meeste voortgang boeken door tijd te besteden aan het zorgvuldig voorbewerken van een afbeelding en het zoveel mogelijk verwijderen van ruis. Dezelfde ruis die Tesseract belemmert om de tekst eruit te halen, belemmert vaak ook commerciële alternatieven om tekst correct te herkennen.
Het verwijderen van ruis uit afbeeldingen voor OCR-doeleinden vereist meestal veel vallen en opstaan. Een manier om dit probleem aan te pakken is door Tesseract zelf te trainen zodat het meer vertrouwd raakt met het type afbeeldingen en de soort tekst waarmee je werkt. Het zal dan leren wat ruis is en wat daadwerkelijk tekst is, en daardoor de ruis zelf filteren.
In het volgende deel gaan we hier verder op in en bespreken we hoe je Tesseract kunt trainen om karakters te herkennen. Dit is vooral handig als er een specifiek lettertype in een document wordt gebruikt dat Tesseract niet nauwkeurig kan herkennen, of als er handgeschreven tekst aanwezig is. We zullen dan direct machine learning toepassen om de nauwkeurigheid van de Tesseract OCR-motor te verbeteren.
Delen