Optical Character Recognition (OCR) with Python and Tesseract 4: An introduction
Introduction
This tutorial is an introduction to optical character recognition (OCR) with Python and Tesseract 4. Tesseract is an excellent package that has been in development for decades, dating back to efforts in the 1970s by IBM, and most recently, by Google. At the time of writing (November 2018), a new version of Tesseract was just released - Tesseract 4 - that uses pre-trained models from deep learning on characters to recognize text. This version can not only recognize scanned characters with great accuracy but also handwritten text, and performs much better than Tesseract 3. OCR is especially relevant for scanned images that contain text. Historical documents, for instance, are often available in scanned form but have not been digitalized yet. You may also want to scan documents yourself and extract the content from them for analysis.
Installing tesseract
Unix systems installation
Installing Tesseract is relatively straightforward for unix-based systems as you can download pre-built binaries. Install them on Mac OS X with:
brew install Tesseract --HEAD
The --HEAD parameter is added to make sure you get the latest version of Tesseract 4, which came out of beta status this month.
And on Ubuntu it can be installed as follows:
sudo apt install tesseract-ocr
sudo apt install libtesseract-dev
If you are working on another Linux distribution, please consult the installation guide here:
https://github.com/tesseract-ocr/tesseract/wiki.
Windows installation
In Windows you'd have to go through an installation procedure.
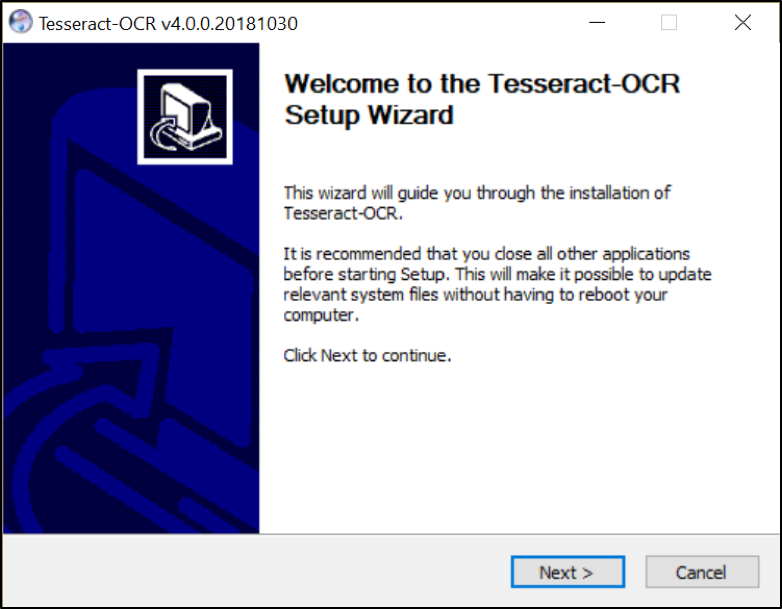
If you prefer using a language other than English, you can download additional script and language data whilst using the installer. By default, Tesseract will not be included in PATH variable which means you have to go to the installation folder of Tesseract and execute from there. You can also add the tesseract.exe file to the PATH environment variable so it is executable from anywhere in Windows.
Verify install
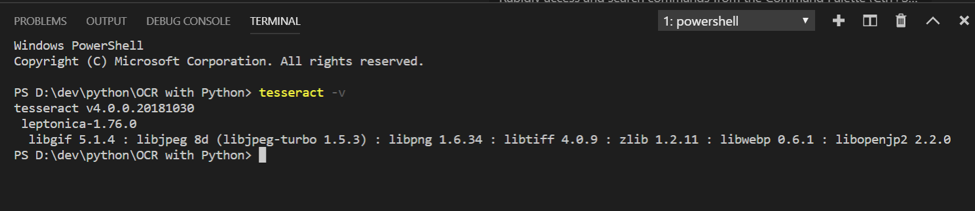
To verify you have installed Tesseract correctly, run the following command in the terminal. It should display the Tesseract version and the list of compatible libraries.
Using the Tesseract standalone binary
Tesseract itself is a standalone binary, hence it does not depend on a Python environment as such. There are wrappers for Tesseract in Python however, which we will get to in the next section. First, to show the use of the Tesseract binary, we'll supply it with an image with clear text. from the text itself, hence this is a relatively easy image for optical character recognition OCR task.

Save the image by right clicking on it and selecting 'Save Image as'. Then enter the following command in your terminal, or PowerShell in Windows (add 'stdout' without parantheses to end of line if you are in Windows):
tesseract 'your path to the image>'
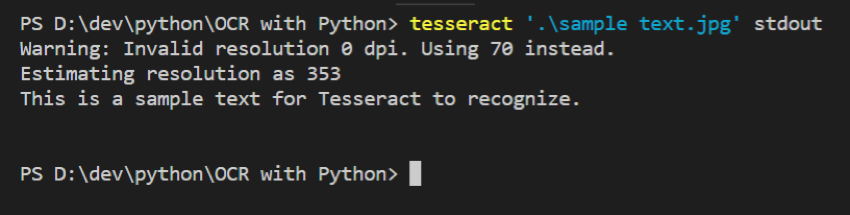
And you should see output similar to the output in the image below. Tesseract extracted the text "This is a sample text for Tesseract to recognize" from the image with 100% accuracy.
If there’s noise in an image such as a blurry background, Tesseract generally still performs well but will often fail to identify some characters. It may miss out on certain letters or misclassify stains as letters. You then need to remove noise first before OCR, applying techniques from feature extraction or machine learning algorithms to separate noise from text, which you can do with some Python code
To do that, rather than running Tesseract from the shell as a standalone binary, Tesseract needs to be integrated into a large framework of code, which we will get into in the next section by using Tesseract wrappers in Python. You can then also write apps that involve Tesseract and OCR, for instance mobile scanner apps.
Using Tesseract in Python
Installing Pytesseract
Pytesseract is an excellent wrapper for Tesseract. TesserOCR is another one, but at the time of writing has not yet been updated for Tesseract 4 and only works with Tesseract 3. We’ll use pip to install the pytesseract package. Using a virtual environment is recommended so that we can separate different projects but this is not necessary. To proceed, run the following commands in your command prompt:
pip install virtualenv
virtualenv env
You can use any name replacing “env”. Next, activate the virtual environment in the shell (you can also skip this):
source activate env/activate/bin
If the environment is activated, the terminal should show (env) at the beginning of the line, such as:
- (env) D:\dev\
We will also install pillow, which is an image processing library in Python, as well as pytesseract itself:
pip install pillow
pip install pytesseract
Usage
Create a python file, for instance 'ocr.py', or create a new Jupyter notebook, with the following code:
import os
from PIL import Image
import pytesseract
import argparse
import cv2
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True, help="path to image that will be processed by OCR / tesseract")
ap.add_argument("-p", "--preprocess", type=str, default="thresh", help="preprocessing method that is applied to the image")
args = vars(ap.parse_args())
The first 5 lines import the necessary libraries. Loading and processing an image with Python and PyTesseract requires the Image class from the PIL library. The rest of the lines are used to parse the arguments that we supply from the command line when running the Python file (these can fed to the code in a Jupyter notebook as well). The arguments are:
- image: The system path to the image which will be subject to OCR / tesseract
- preprocess: The preprocessing method that is applied to the image, either thresh or blur. More methods are available but these 2 are most often applied and suffice for this guide.
Now we load the image into the Python kernel (in memory). Then, as we are not interested in colors for OCR purposes, we transform it to grayscale. Hence we are reducing the 'information' in the graph that is not necessary for our purpose, namely OCR. This is key to many machine learning purposes. We use the OpenCV package for this, which is the most advanced and most frequently used image processing package in Python. Afterwards we save new image to disk.
# The image is loaded into memory – Python kernel
image = cv2.imread(args["image"])
# Convert to grayscale
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# preprocess the image
if args["preprocess"] == "thresh": gray = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
# blur the image to remove noise
elif args["preprocess"] == "blur": gray = cv2.medianBlur(gray, 3)
# write the new grayscale image to disk
filename = "{}.png".format(os.getpid())
cv2.imwrite(filename, gray)
The aim of the threshold above is to distinguish the foreground containing the text from the background. This is particularly useful when dark text in an image is printed on top of a gray or otherwise colored surface. The 'blur' preprocessing similarly helps in reducing noise. We now load the image again and run it through Tesseract using the pytesseract wrapper:
# load the image as a PIL/Pillow image, apply OCR
text = pytesseract.image_to_string(Image.open(filename))
print(text)
# show the output image
cv2.imshow("Image", image)
cv2.imshow("Output", gray)
cv2.waitKey(0)
The 'pytesseract.image_to_string' extracts the text string from the grayscale image file and stores it in the 'text' variable. Afterwards you can further process the text. For instance, you can run it through a spell checker to correct letters that were wrongly identified by tesseract. This is the basic setup of a Python file that incorporates Tesseract to load an image, remove noise and apply OCR to it.
We will now apply these steps and some further noise-cleaning steps to extract the text from an image with both a noisy and blurry background and blurry text.
OCR with noisy and blurry images
We’ll try to apply OCR the image below.

In this image is no clean, clear white background. Rather the background to some extent overlaps with the text. The human eye can still clearly identify the text, so tesseract, given that it was trained with deep learning, should be able to as well.
Right click on the image, select ‘Save Image as’ and save it to a folder with the filename ‘ocr-noise-text-1.png’.
Now run it through the Tesseract binary without any preprocessing, using the prevous code to execute Tesseract in the shell:
tesseract ocr-noise-text-1.png
As you can see from the noisy output, Tesseract isn’t able to extract the text accurately.
We now preprocess the image to make the text stand out as much as possible from the background. This is done using a combination of thresholding, as dealt with earlier, and morphological adjustments. We'll again use OpenCV for this.
As before, the image is first converted to grayscale. A Gaussian blur is then applied to further take out noise. The other operations concern the text itself, thresholding and dilating it to separate the text from the background. The final step inverts the image color wise, from black to white and vice versa (so the text is black in the end and displayed on a white background). See for the excellent solution on StackOverflow here.
import cv2
image = cv2.imread('./ocr-noise-text-1.png', 0)
imgBlur = cv2.GaussianBlur(image, (9, 9), 0)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))
imgTH = cv2.morphologyEx(imgBlur, cv2.MORPH_TOPHAT, kernel)
imgBin = cv2.threshold(imgTH, 0, 250, cv2.THRESH_OTSU)
imgdil = cv2.dilate(imgBin, kernel)
imgBin_Inv = cv2.threshold(imgdil, 0, 250, cv2.THRESH_BINARY_INV)
cv2.imwrite('./ocr-noise-text-2.png', imgBin_Inv)
cv2.waitKey(0)
The new, noise-corrected image without the blurry background is saved to the disk as ‘ocr-noise-text-2.png’. It looks as follows:

Now we run this image through pytesseract, using the following code similar to the code earlier:
text = pytesseract.image_to_string(Image.open(‘./ocr-noise-text-2.png’))
print(text)
As can be seen from the output, Tesseract now correctly extracts the text from the image even though the text itself is still blurry and some of the pixels in the letters are disconnected. Hence upon pre-processing the image, the pre-trained models in tesseract, that have been trained on millions of characters, perform pretty well. Hence machine learning is very useful for OCR purposes.
Conclusion
This tutorial is a first step in optical character recognition (OCR) in Python. It uses the excellent Tesseract package to extract text from a scanned image. This technique is relevant for many cases. For instance, historical documents that have not been digitalized yet, or have been digitalized incorrectly, come to mind.
There are alternatives to Tesseract such as Google Vision API or Abbyy, but these are not free and open source. Often you can make most progress by spending time on preprocessing an image carefully and taking out as much as noise as possible. The same noise that prevents Tesseract from being able to extract text also often prevents commercial alternatives from extracting text correctly.
Removing noise from images for OCR purposes usually involves a lot of trial and error. One way to deal with this problem is to train Tesseract yourself so that it gets more familiar with the type of images and type of text you're working with. It will then learn what is noise and what is actually text and hence filter out noise by itself.
In the next section we will get into this, focusing on how you can train Tesseract to identify characters. This is particularly handy if a certain font is used in a certain document that Tesseract doesn’t recognize accurately, of if handwritten text is present. Hence we’ll then directly apply machine learning to improve the accuracy of the Tesseract OCR engine.
Share